Data Build Tools
Core Foundations of dbt
- What is dbt
- ELT vs ETL
- dbt Project Structure
- dbt_project.yml
- profiles.yml
- dbt Core vs dbt Cloud
- dbt Environment Management
Models and Materializations
dbt Environment Management: Multi-Target Strategies for Dev, Staging & Prod
In a modern analytics engineering workflow, you rarely want to run all your transformations in a single environment. Mistakes in development or experiments could break production dashboards or corrupt user-facing data. Hence, managing multiple environments (dev, staging, production) is a foundation of robust dbt architecture.
In dbt, “environment management” often means configuring targets (in profiles.yml or in dbt Cloud) and using those to isolate schemas, credentials, and permissions per stage. Handling multiple targets correctly lets you:
- Develop and test safely without interfering with production
- Promote changes in a controlled pipeline (dev → staging → prod)
- Maintain consistent logic across environments
- Enforce access control, permissions, and testing before release
In this article I’ll cover:
- Core concepts of environment & target management in dbt
- How to configure dev / staging / prod in
profiles.yml(or dbt Cloud) - Techniques & patterns (e.g. schema naming, conditional logic)
- Three example scripts / patterns per concept
- A “Merquine-style” diagram to visualize flows
- Memory / study tips (for exam / interview)
- Why this matters, pitfalls, best practices
Let’s start.
1. Core Concepts: Targets, Environments, and Profiles
What is a “target” in dbt?
- In dbt Core, a target is a named configuration in your
profiles.ymlthat defines how and where dbt connects to your data warehouse (host, database, schema, credentials, etc.). ([docs.getdbt.com][1]) - You pick which target to run via
dbt run --target <target_name>(or via settingtarget:inprofiles.yml). - The default target is often
dev, so that developers’ changes go to a non-production schema. ([docs.getdbt.com][1])
Example minimal profiles.yml snippet:
my_project: target: dev outputs: dev: type: postgres host: <dev_host> user: <dev_user> password: <dev_pass> dbname: <dev_db> schema: analytics_dev prod: type: postgres host: <prod_host> user: <prod_user> password: <prod_pass> dbname: <prod_db> schema: analytics_prodHere, there are two targets: dev and prod.
What is an “environment” in dbt (Cloud and Core)?
- In dbt Cloud, an environment is a higher-level abstraction: it combines a target (or outputs) + orchestration settings + version selection + branch rules. ([docs.getdbt.com][2])
- A dbt project can have exactly one development environment but can have multiple deployment/deployment-type environments (General, Staging, Production) in dbt Cloud. ([docs.getdbt.com][2])
- One of these environments in dbt Cloud can be marked as Production for special metadata and behavior. ([docs.getdbt.com][3])
Thus, you can think:
- dbt Core: you manage multiple targets via
profiles.yml - dbt Cloud: you manage environments, each tied to a target / branch / orchestration + credentials
How many and what types of environments?
According to dbt Cloud docs:
| Environment Type | Purpose | Quantity per project | |
|---|---|---|---|
| Development (for local / CLI) | Used in Studio or CLI | 1 | |
| General (deployment) | For ad hoc / scheduled jobs | many | |
| Staging (deployment) | A test / staging deployment | 1 | |
| Production (deployment) | The live production pipeline | 1 | ([docs.getdbt.com][2]) |
In Core mode, you typically have a few targets (dev, staging, prod) in profiles.yml.
Why separate these?
- To isolate schema/data — dev schemas should not interfere with prod schemas
- To use different credentials/perms — dev users often have broader write access
- To run tests and validations before pushing to prod
- To support CI/CD and promotion workflows (dev → staging → production)
- To avoid accidental overwrites to production assets
Staging adds a middle ground: after dev testing, you validate in staging (which mirrors prod) before final production push. ([docs.getdbt.com][4])
Given that foundation, let’s go into how you configure and use these in practice.
2. Configuring Multiple Targets: dev / staging / prod
2.1 In dbt Core (via profiles.yml)
You define multiple outputs under one profile, and switch with target: or CLI flag.
Example:
my_project: target: dev outputs: dev: type: snowflake account: dev_acc user: dev_user password: "{{ env_var('DEV_PASS') }}" role: DEV_ROLE database: analytics_dev schema: core warehouse: compute_small staging: type: snowflake account: stage_acc user: stage_user password: "{{ env_var('STAGE_PASS') }}" role: STAGE_ROLE database: analytics_stage schema: core warehouse: compute_medium prod: type: snowflake account: prod_acc user: prod_user password: "{{ env_var('PROD_PASS') }}" role: PROD_ROLE database: analytics_prod schema: core warehouse: compute_largeYou might run:
dbt run --target devdbt run --target stagingdbt run --target prod
You can also override target in CI or script by environment variable DBT_TARGET=prod dbt run.
Example 1 (profiles.yml switching):
project_x: target: dev outputs: dev: type: postgres host: localhost user: dev_user password: "{{ env_var('DEV_PW') }}" dbname: test_db schema: schema_dev prod: type: postgres host: prod.postgres.cloud user: prod_user password: "{{ env_var('PROD_PW') }}" dbname: prod_db schema: schema_prodThen commands:
dbt run # uses dev by defaultdbt run --target prod # runs on prodExample 2 (with staging):
my_proj: target: staging outputs: dev: … staging: … prod: …Then switch to prod via CLI.
Example 3 (overriding in CI script):
export DBT_TARGET=proddbt rundbt testInternally, dbt uses this.target (or target.name) within macros or conditional logic for environment-specific operations.
2.2 In dbt Cloud (via Environments)
If you host your project in dbt Cloud, you define Environments via UI (or APIs). Each environment is tied to:
- A branch (or “use a custom branch”)
- A dbt version track
- Credentials / connection details
- Optionally be marked as Production
- Which target / database it points to
You then schedule jobs in these environments (e.g. a job in the Staging environment, and one in Prod). You separate jobs by environment rather than try to mix deployment in one job. ([docs.getdbt.com][3])
You can also leverage environment-level deferral and metadata segmentation: the environment that created a model can be tracked and used in incremental logic or dependency logic. ([docs.getdbt.com][3])
In dbt Cloud:
- Create a Staging environment, assign credentials, branch, etc.
- Create or mark your Production environment, ensuring it’s flagged as prod.
- Split jobs between staging / prod environments (don’t run both in one).
- Use lower-privilege credentials in staging, tighter controls in prod.
This segmentation allows clear separation, role-based permissions, and easier debugging.
3. Techniques & Patterns: Environment-aware Logic
With multiple targets, you often need logic that behaves differently based on the environment (e.g. shorter time windows in dev, limiting data subset, skipping heavy transformations). Here are patterns:
3.1 Conditional logic via target.name or var() checks
Within a .sql model or macro, you can conditionally branch:
{% if target.name == 'dev' %} select * from {{ source('raw_schema', 'events') }} where event_date > current_date - 30{% elif target.name == 'staging' %} select * from {{ source('raw_schema', 'events') }} where event_date > current_date - 90{% else %} select * from {{ source('raw_schema', 'events') }} -- full table{% endif %}Or use var('is_incremental', false) or var('environment', 'dev').
3.2 Schema naming / prefix functions
You might create a macro that prefixes schemas per environment:
{% macro generate_schema_name(custom_schema_name, node) %} {% if target.name == 'dev' %} dev__{{ custom_schema_name }} {% elif target.name == 'staging' %} staging__{{ custom_schema_name }} {% else %} prod__{{ custom_schema_name }} {% endif %}{% endmacro %}Then every model writes into {{ generate_schema_name('core') }} or similar.
3.3 Deferral / cross-project references in staging environment
dbt supports deferral: in staging/CI, you can defer to production models rather than rebuilding them, reducing overhead. ([docs.getdbt.com][3])
For example, you have a macro:
-- in dbt_project.ymlmodels: +defer: "{{ target.name == 'staging' }}"Then in staging, it will reference production artifacts for unchanged models, speeding up builds.
Alternatively, use {{ ref('other_project.model', is_dev=false) }} in staging context.
4. Example Programs / Scripts per Concept
Below are three example code snippets for each of the above three techniques (conditional logic, schema naming, deferral), showing how they might work in a real project.
4.1 Conditional logic examples
Example A: limiting rows in dev
-- models/orders_recent.sql
{% set cutoff = (target.name == 'dev') |ternary('event_date > current_date - 7', 'event_date > current_date - 365')%}
select *from {{ source('raw', 'orders') }}where {{ cutoff }}In dev you only see the last 7 days; in prod you see full year.
Example B: switching join tables
-- models/enrich_customers.sql
{% if target.name == 'dev' %} with dim as ( select * from {{ ref('dim_customer_small') }} ){% else %} with dim as ( select * from {{ ref('dim_customer') }} ){% endif %}
select a.*, dim.attrfrom {{ ref('raw_events') }} aleft join dim on a.customer_id = dim.idIn dev, join to a smaller dimension.
Example C: toggling features
-- models/calc_metrics.sql
{% set flag = var('enable_new_metric', false) %}
select user_id, count(*) as total_events, {% if flag and target.name == 'prod' %} sum(case when event_type = 'purchase' then 1 else 0 end) as total_purchases {% endif %}from {{ ref('events') }}group by user_idYou only enable a new metric in prod if var is set.
4.2 Schema naming / prefix macro examples
Example A: per-environment prefix
-- macros/schema_prefix.sql{% macro schema_prefix() %} {% if target.name == 'dev' %} dev_ {% elif target.name == 'staging' %} staging_ {% else %} prod_ {% endif %}{% endmacro %}Use in dbt_project.yml:
models: +schema: "{{ schema_prefix() }}analytics"Example B: environment-based suffix
{% macro suffix_schema(base_schema) %} {{ base_schema }}__{{ target.name }}{% endmacro %}Then:
models: +schema: "{{ suffix_schema('analytics_core') }}"You’ll get analytics_core__dev, analytics_core__prod.
Example C: dynamic project name insertion
{% macro custom_schema_name(custom_schema_name, node) %} {% if target.name == 'dev' %} {{ env_var('USER') }}_{{ custom_schema_name }} {% else %} {{ custom_schema_name }} {% endif %}{% endmacro %}This way, each developer writing in dev gets own schema namespace (e.g. alice_core, bob_core).
4.3 Deferral / cross-project reference examples
Example A: deferring to prod in staging
models: +defer: "{{ target.name == 'staging' }}"With that, during staging runs, dbt will not rebuild models that exist in production artifacts; it will instead reference production ones.
Example B: conditional cross-project ref
{% if target.name == 'staging' %} select * from {{ ref('prod_project.some_model') }}{% else %} select * from {{ ref('local_project.some_model') }}{% endif %}In staging you refer to prod version; in dev you rebuild locally.
Example C: macro for ref or defer
{% macro smart_ref(model_name) %} {% if target.name == 'staging' %} {{ ref('prod_project.' ~ model_name) }} {% else %} {{ ref(model_name) }} {% endif %}{% endmacro %}
-- Then in models:select *from {{ smart_ref('orders') }}Thus staging uses production version, dev rebuilds.
5. Merquine (Flow / Architecture) Diagram
Below is a conceptual diagram (Merquine-style flow) to visualize how dev → staging → prod promotion works, showing branching, environment, and flows.
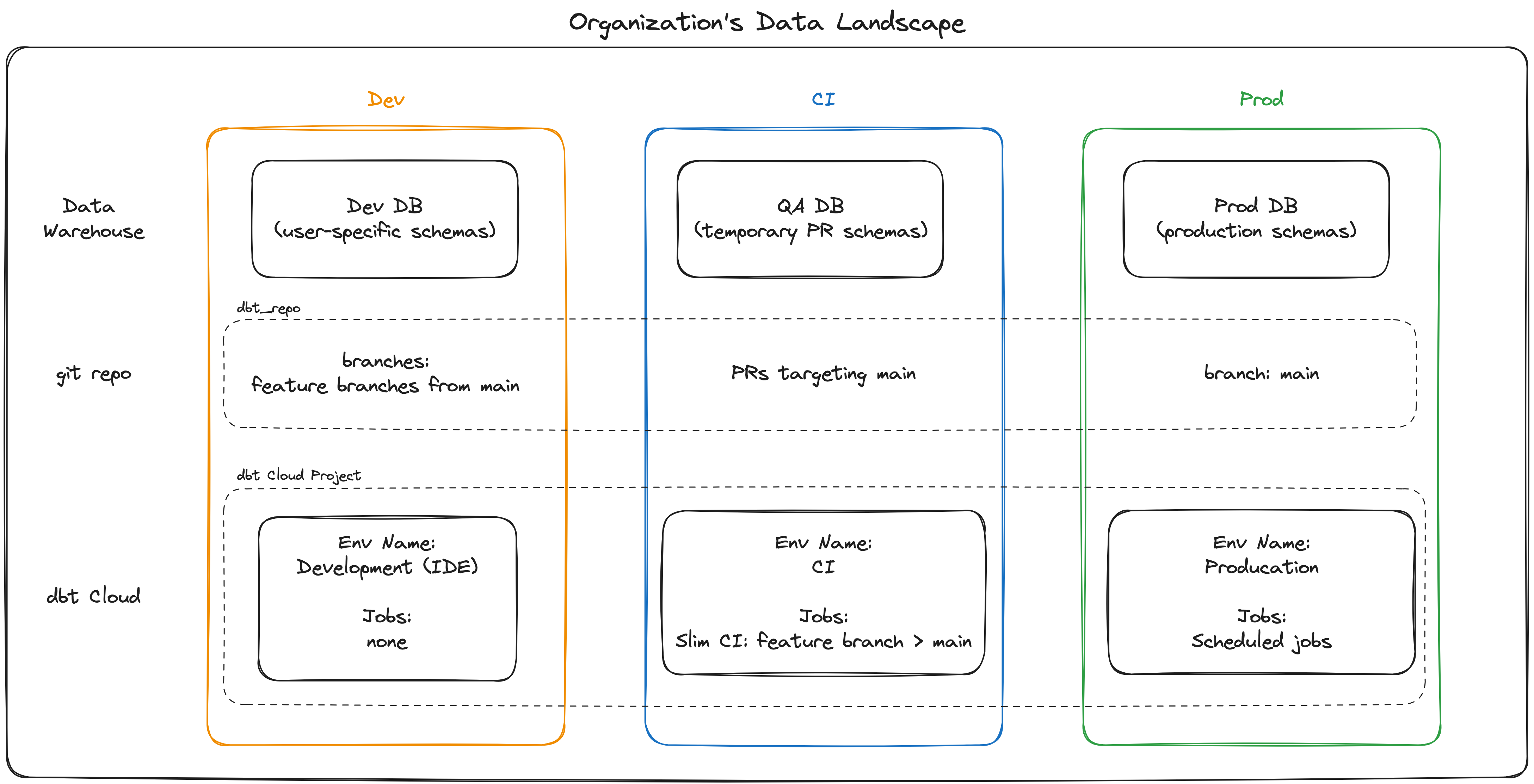
Here’s a textual equivalent:
Developer Branches (feature branches) ↓dev environment (personal / shared dev target) ↓ (after tests)merge → staging branch/job ↓staging environment (mirrors prod, uses deferral, validation) ↓ (after signoff)merge → main ↓prod environment (live production pipeline)In practice:
- Dev: developers work on feature branches, test locally / in dev target
- When ready, open PR → merge into
stagingbranch - A job in the staging environment runs full transformations, integration tests
- Once validated, staging merges into
main→ triggers prod environment job - Prod environment uses production credentials, writes to live schema
This pipeline ensures safe progression through environments, with isolation at each step.
6. Memory & Interview / Exam Tips
When preparing for interviews or exams, you want to be able to recall core ideas, patterns, and advantages. Here are techniques:
-
Mnemonic “DSP”
- Dev
- Staging
- Prod Whenever asked, you enumerate: dev → staging → prod.
-
“Three Pillars” of environment management
- Isolation (schemas, credentials)
- Promotion pipeline (dev → staging → prod)
- Environment-aware logic (conditional code, deferral)
-
Flash-card style
- Q: What is a “target” in dbt?
A: A named output configuration in
profiles.yml. - Q: What does
dbt run --target stagingdo? A: Runs models using staging configuration. - Q: Why use staging environment? A: Validate changes before pushing to production, isolate dev from prod.
- Q: What is a “target” in dbt?
A: A named output configuration in
-
Whiteboard diagram practice
- Draw the flow dev → staging → prod
- Label where credentials differ, where schema naming changes
- Show how deferral or cross-project references work
-
Compare to software dev environments
- Just like code has dev / qa / staging / prod in apps, you can map that same mental model to dbt. Many interviewers expect you to make that analogy.
-
Practice explaining aloud
- “In dbt, environment management means using targets and environment logic so that your incremental or heavy transforms in prod don’t run in dev.”
- Walk through an example: “In dev, I limit to last 30 days; in prod I run full data load.”
-
Edge cases / pitfalls
- Be ready to discuss: what if your dev/staging use different DB types? (you may need compatible SQL) ([Stack Overflow][5])
- Or how you manage sensitive credentials (use environment variables).
- Or how to prevent developers from accidentally writing to prod.
By internalizing the three pillars and walking through example scenarios, you can handle both conceptual and coding questions.
7. Why It’s Important (and Common Mistakes to Avoid)
Why this is critical
- Data integrity & trust: If dev changes accidentally touch production, you risk corrupting datasets or dashboards.
- Safe experimentation: Analysts/engineers can innovate without fear of breaking live systems.
- Scalable team workflows: With multiple people, you need clear gates before pushing to prod.
- CI/CD & governance: It enables a robust release process with validation steps.
- Performance & cost optimization: You can run lighter transformations in dev / staging to save compute costs.
- Auditability & traceability: You can track which environment produced a given model or artifact (especially in dbt Cloud). ([docs.getdbt.com][3])
Common pitfalls & how to avoid them
-
Using same schema for all environments
- Leads to collisions. Always namespace or prefix schemas.
-
Hardcoding credentials in
profiles.yml- Use environment variables (
env_var()) to avoid leaks.
- Use environment variables (
-
Mixing jobs for staging & production in same environment
- Instead, split jobs per environment in dbt Cloud. ([docs.getdbt.com][3])
-
Unconditional heavy transformations in dev
- Use conditional logic or limiters for dev runs.
-
Relying only on dev → prod without staging
- Skipping staging removes the safe check barrier.
-
Unsupported SQL divergences
- If dev DB / prod DB use different dialects, your logic must be compatible or abstracted.
-
Overcomplicated branching / environment logic
- Keep conditional macros and schema naming simple and documented.